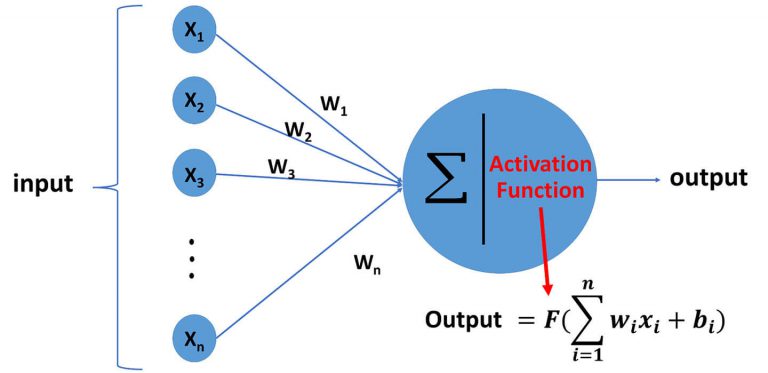
AIEX Deep Learning platform provides you with all the tools necessary for a complete Deep Learning workflow. Everything from data management tools to model traininng and finally deploying the trained models. You can easily transform your visual inspections using the trained models and save on tima and money, increase accuracy and speed.
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
Revolutionary Indsutry Transformation
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
TensorRT is a library developed by NVIDIA for faster inference on NVIDIA graphics processing units (GPUs). TensorRT is built on CUDA, NVIDIA’s parallel programming model. It can provide 4 to 5 times faster inference for many real-time services and embedded applications. According to the documentation, it provides inference performance 40 times faster than that of a CPU.
The optimization that TRT applies to deep learning models will be examined in this article.
What kind of optimization does TensorRT do?
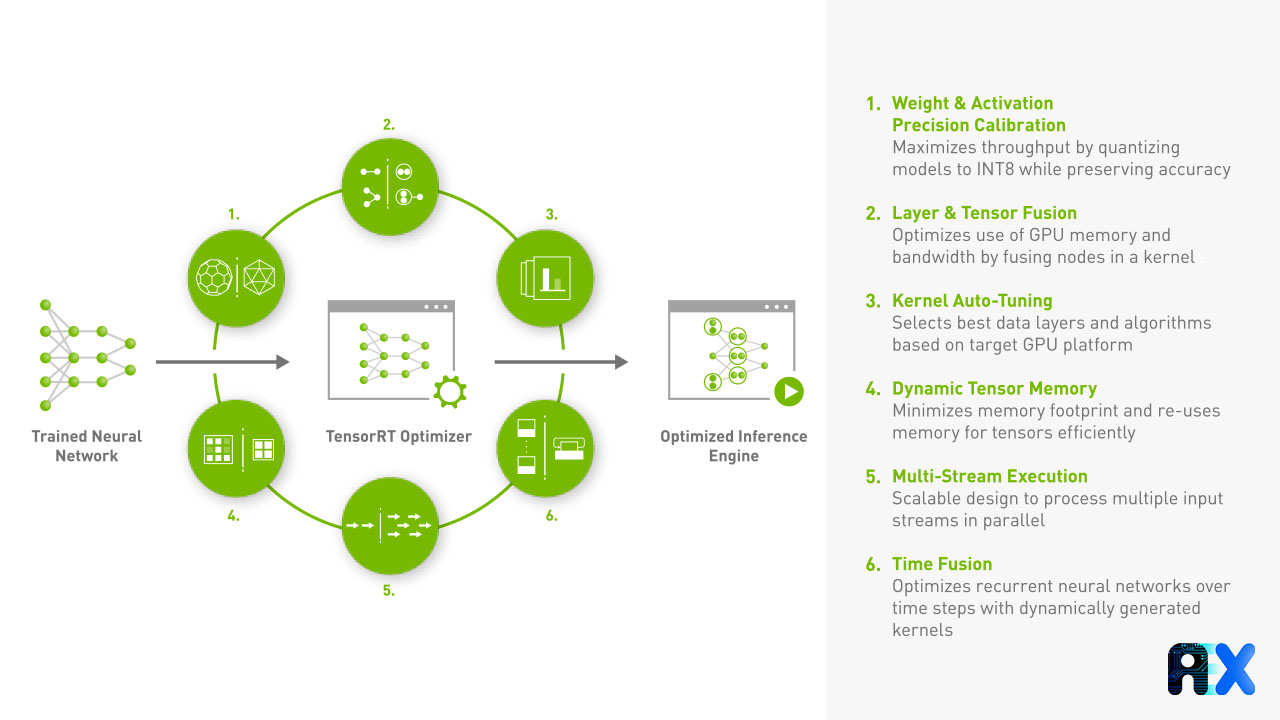
TensorRT performs six different kinds of optimization to increase the throughput of deep learning models. In this article, we’ll cover all five types of optimizations.
Figure 1. Types of optimizations performed by TensorRT to optimize models. Source
Weight and Activation Precision Calibration
During training, parameters and activations are in FP32 (Floating Point 32) precision. FP16 or INT8 precision should be used to convert them. In this optimization, FP32 precision is converted to FP16 or INT8, which significantly reduces model size and lowers latency.
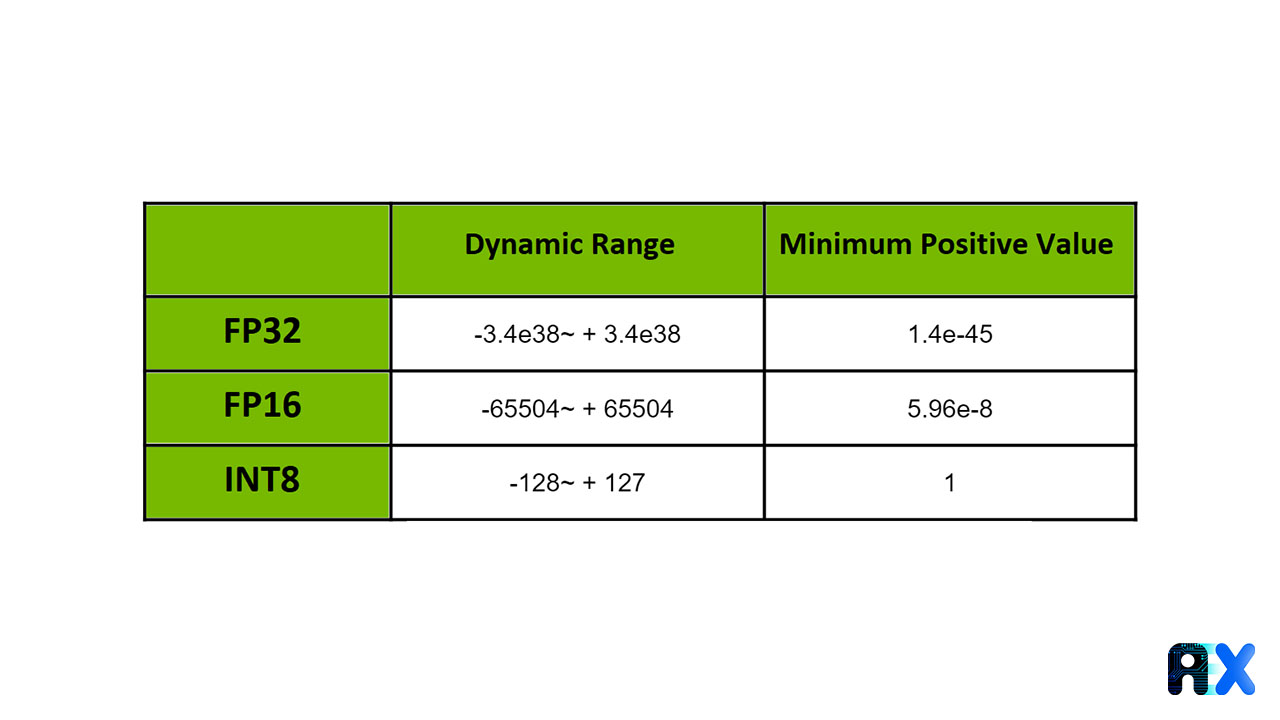
Figure 2. The dynamic range of different precisions, Source
Some of our weights will shrink due to overflow when converting to FP16 (lower precision) as FP16’s dynamic range is smaller than FP32’s. However, experiments show this has little impact on accuracy.
But, how do we justify that? FP32 is known to be highly precise. In general, weights and activation values are noise-resistant. The model makes an effort to maintain the features required for inference while training. So, discarding useless items is essentially a built-in process. We, therefore, assume that noise is produced by the model during downscaling to a lower degree of precision.
When converting to INT8 precision, a similar method of clipping overflowing weights won’t work. Because the range of INT8 values is so narrow, from [-127 to +127], the majority of our weights will overflow and change to lower precision, significantly decreasing the accuracy of our model. Therefore, we use scaling and bias to map those weights into INT8 precision.
Layers and Tensor Fusion
Any deep learning framework that uses graphs must perform a similar computation automatically while running the graph. Therefore, to get around this problem, TensorRT uses layer and tensor fusion to optimize GPU memory and bandwidth by fusing kernel nodes vertically or horizontally (or both). This lowers the overhead and the cost of reading and writing the tensor data for each layer. Here is a straightforward analogy: rather than purchasing three items from the market over the course of three trips, we do so in a single trip.
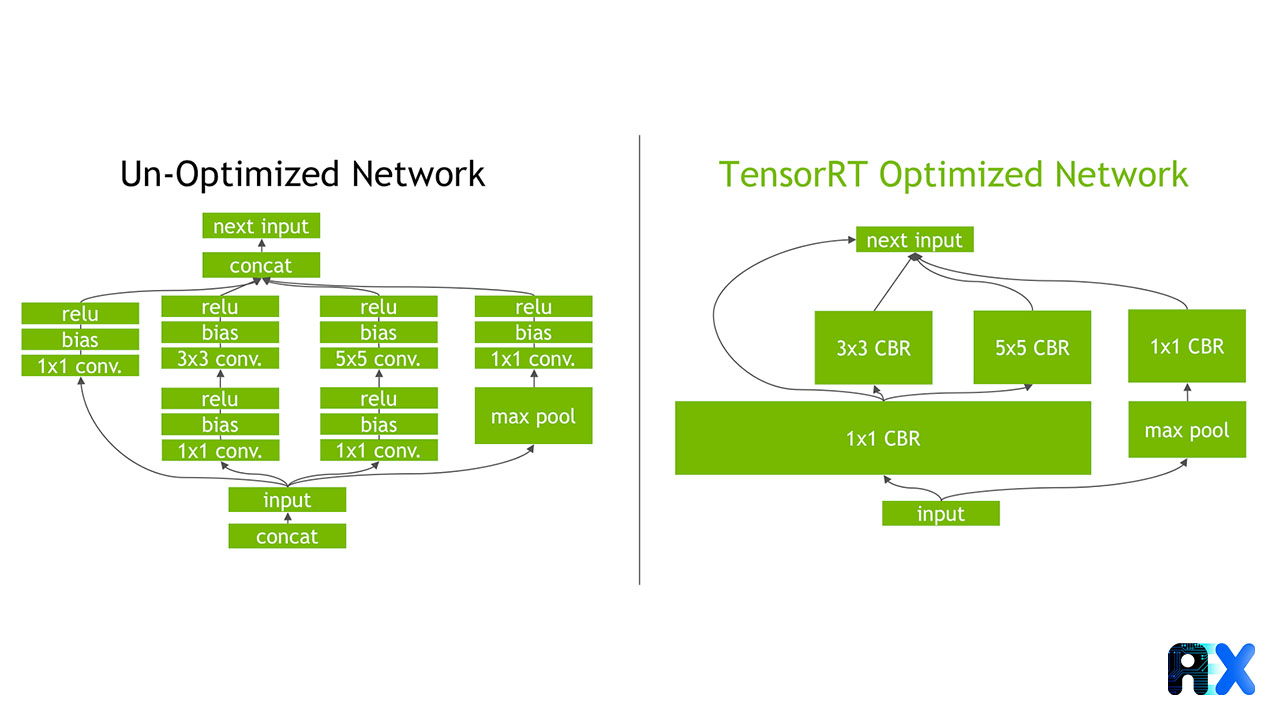
Figure 3. On the GoogLeNet Inception module graph, TensorRT’s vertical and horizontal layer fusion minimizes computation and memory overhead. Source
As previously demonstrated, TensorRT identifies all layers with similar input and filter sizes but different weights, and then it combines them to create a single 1×1 CBR layer, as seen on the right side of figure 3.
Kernel auto-tuning
While optimizing models, there are certain kernel-specific optimizations that can be performed during the process. Depending on the target GPU platform, the best layers, algorithms, and batch sizes are chosen. For instance, there are several ways to perform a convolution operation, but TRT chooses the one that will be most effective on the chosen platform.
Dynamic Tensor Memory
TensorRT improves memory reuse by allocating memory to the tensor only for the duration of its operation. This lowers memory footprints and avoids the overhead associated with the allocation, resulting in quick and effective execution.
Multiple Stream Execution
TensorRT is made to handle several input streams concurrently. This is basically Nvidia’s CUDA stream.
Subscribe to our newsletter and
get the latest practical content.
You can enter your email address and subscribe to our newsletter and get the latest practical content. You can enter your email address and subscribe to our newsletter.