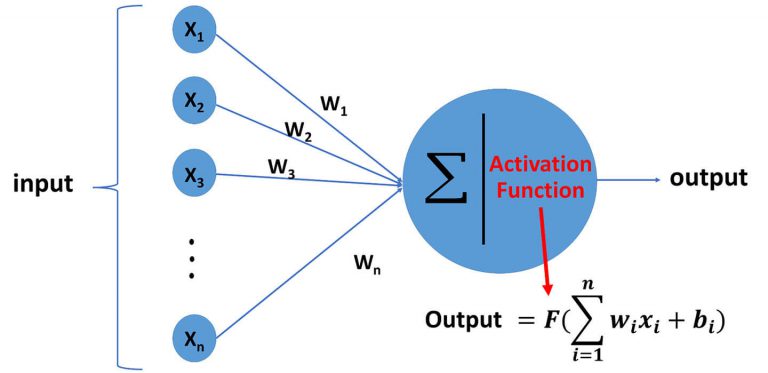
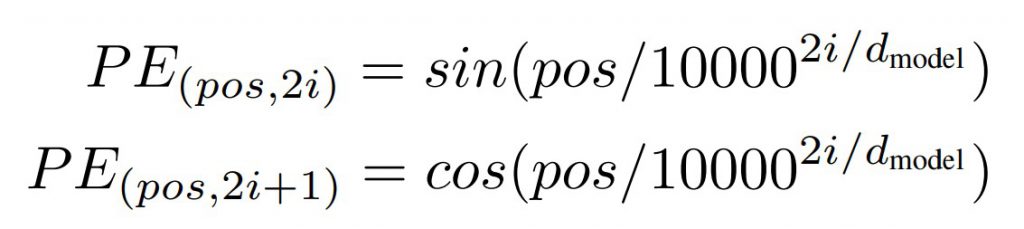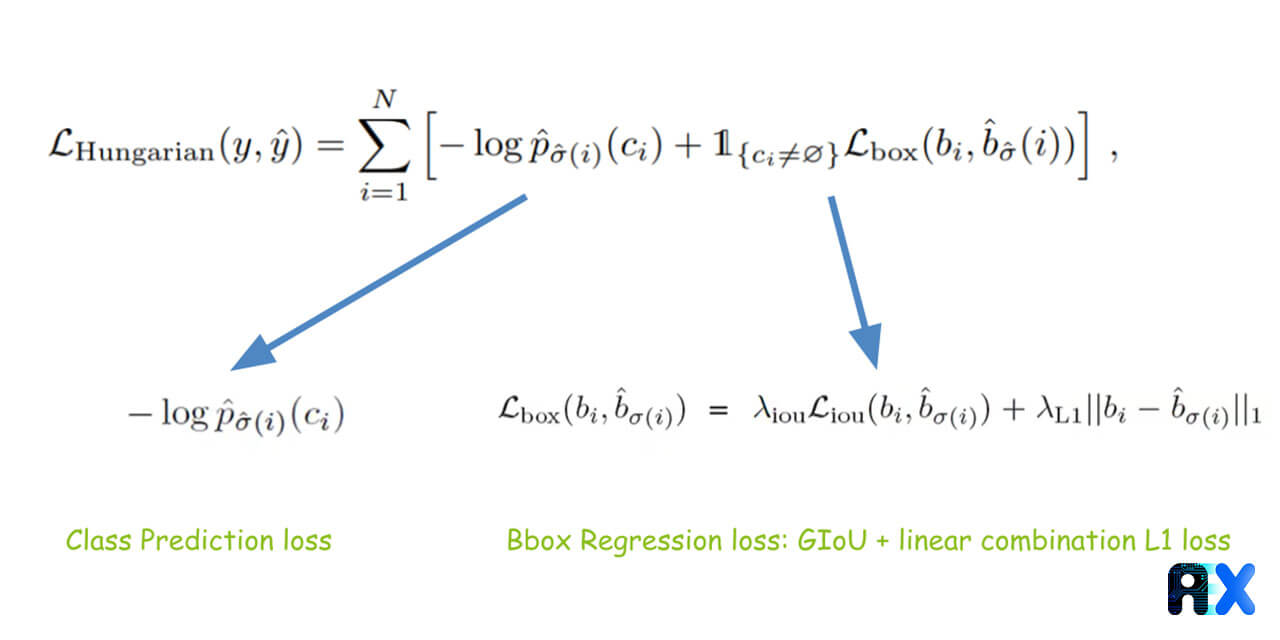AIEX Deep Learning platform provides you with all the tools necessary for a complete Deep Learning workflow. Everything from data management tools to model traininng and finally deploying the trained models. You can easily transform your visual inspections using the trained models and save on tima and money, increase accuracy and speed.
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
Revolutionary Indsutry Transformation
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
The story starts with sequence-to-sequence problems, where a simple architecture like that in Figure 1 was first proposed. Due to the nature of this architecture, the words and the information at the beginning of the source sentence did not transfer well to the decoding part.
The attention mechanism was first introduced in 2015 in a paper written by Bahdanau to solve the problem of machine translation. In addition to solving the main problem, the attention mechanism also helps to solve the alignment problem (determining which parts of the input string are related to each produced output). The method proposed by Bahdanau has the following steps:
Coding the Input Vector (Encoding)
The first step is to convert the words into coded vectors. Bahdanau used a bidirectional recurrent neural network to merge hidden states after each word was entered.
Alignment
As soon as the input words have been encoded, it is time to decode them. When generating each output word, it is necessary to determine which input words are more important. Therefore, at this stage, we need a function that assigns a score to each word based on the words that have been generated so far and their vectors.
Weighting
The weight value is calculated by applying the softmax function to each attention score.
Generating the Context Vector
Using the generated vector and its cache, the decoder network produces the output word in the time step.
Transformers
In 2017, Transformer models were introduced in the article “Attention is all you need“. As a result of the introduction of transformative models, recursive units could be eliminated so that sequence-to-sequence problems could be solved by focusing only on the attention mechanism. This makes it possible for us to process different components of the sequence in parallel. We will examine the architecture of these models in order to gain a better understanding of them. Transformer networks are shown in the figure below:
Figure2. The general architecture of a Transformer Network. Source
In order to process different types of data in neural networks, they must be converted to numbers. The first step is to obtain the embedding of the words of the sentence in the source language (Considering transformers are the first NLP applications, the initial explanations will be given for this step). In transformer models, there is no recursive unit, so words in input sentences can be processed in parallel. It is therefore necessary to provide the position of the word in the sentence (Positional Encoding) as an input. The sine function is used in order to calculate the positional encoding of words in the even positions, and the cosine function calculates the positional encoding of words in the odd positions. By adding word position vectors to their embedding, we have achieved the encoder and decoder inputs.
In the presented formula, pos is the position, i is the dimension, and d is the representation dimension. Source
Encoder
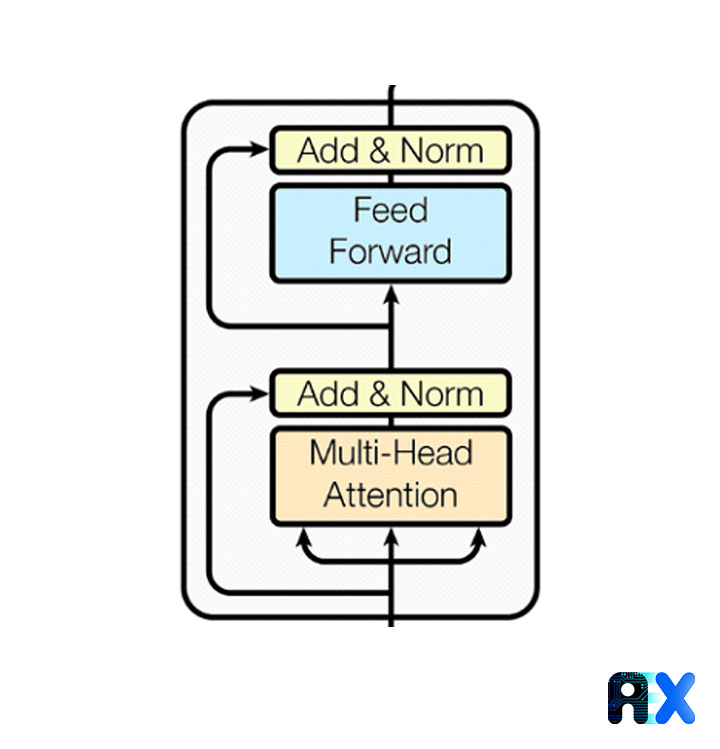
Encoder Networks are designed to understand what a sentence means in the source language. In the below figure, you can see two parts of this module, Multi-head Attention and Feed Forward. Each of these elements will be discussed in the following sections.
During multi-head attention, we deal with three different entities: Key, Value, and Query. Consider the case where you are searching for a specific phrase in a text. In order to find this particular phrase, we need to search the text. As part of the multi-headed attention mechanism, this phrase plays a role similar to a “query”. As part of its algorithm, it compares your search phrase with the title, description, etc. within the text, and after finding the most similar title, it displays the most related one for you. Searched title and description have a role like “key” and the phrase itself has a role like “value” in the multi-headed attention mechanism.
Figure4. Multi-headed attention and scaled Dot-Product Attention block. Source
To create K, V, and Q vectors, the word vector passes through three feed-forward layers with different weights. Then these vectors enter the Scaled Dot-Product Attention block. First, the Dot product of Q and K vectors is calculated to determine how similar they are. Then, by dividing the resulting score by the square root of the length of the input string, the score is normalized to avoid the gradient explosion problem. Then, by applying the softmax function on these values, the weight of each key is determined for each query. Finally, the calculated weights are multiplied by the values of different words to produce the desired output. The image on the left in the figure above shows these steps. The figure below illustrates them as a formula.
Figure5. The scaled Dot-Product Attention block process
Finally, the outputs of these blocks are joined together and processed by a feed-forward layer. The output of the multi-head attention block is added to the original word vectors through residual connection after the positional encoding step. In the end, a layered normalization is applied to the result of this operation.
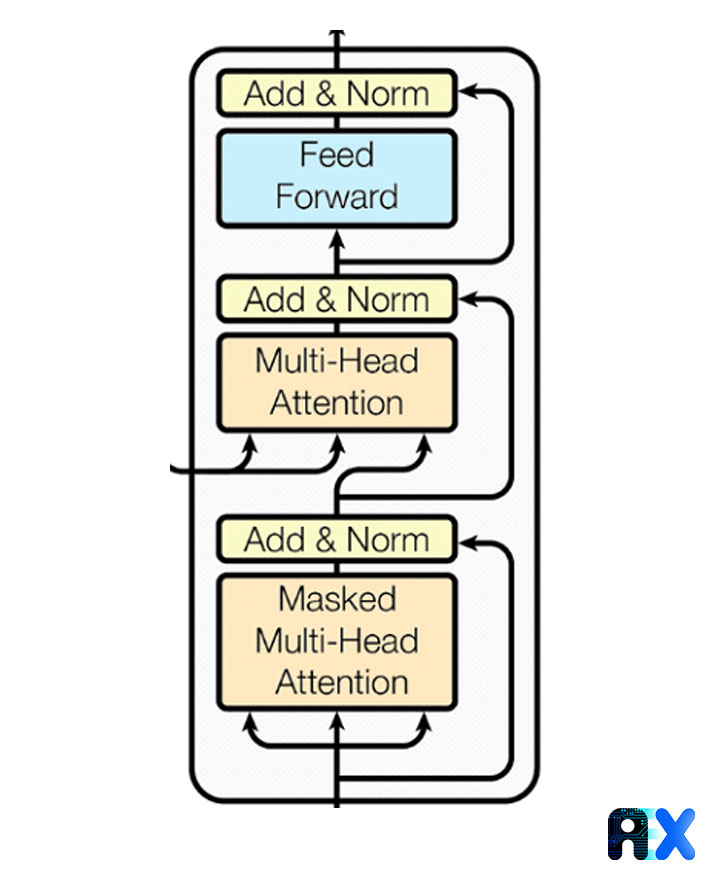
Decoder
The Decoder module produces the output sentence. At each time step, the module generates a new word based on the previous outputs of the encoder. It continues until the word ‘end’ appears, which signifies the sentence’s end. The constituent elements of this module are similar to the encoder module, but its process has some differences. First, the embedding of the previously generated words is extracted and the position vectors are added to them as before. Then, the decoder module starts its work. In the first step, like the encoder module, a self-attention block is used so that the model can have a more detailed analysis of the sentence it has produced so far; But its process is slightly different from other multi-head implementations in converter networks. After the self-attention block, it is necessary for the model to pay attention to parts of the input sentence for more accurate translation. Therefore, in the next attention block, keys and values (Keys & Values) come from the output of the encoder module instead of the previous multi-head attention. Finally, the result of all these steps is given to a feed-forward network for further processing. Note that there are residual connections and layer normalization in all these steps.
DETR: End-to-End Object Detection with Transformers
In 2020, Facebook’s research team introduced object detection with transformers or the DETR algorithm. This algorithm has the ability to recognize 91 classes, which demonstrates its power. This is the first time transformers have been used to detect objects. In the figure below, the overview of the DETR architecture can be seen.
According to the DETR model, the image is first encoded using a convolution Neural Network Encoder, since CNNs are best suited for images. As a result, the image features are retained after passing through a CNN. The feature map of the image is passed to a transformer encoder-decoder, which produces the box predictions. Each box contains a tuple that contains a class and a bounding box. The position of the class NULL or Nothing is also included here.
The problem is that there is no object annotated as class NULL in the annotation. Another major issue is dealing with similar objects next to each other, which is addressed by using bipartite matching loss. A loss is calculated by comparing each class and bounding box with its corresponding class and box, including the none class, for example N is compared with the annotation, including the part added that contains nothing, to make the total boxes N. In order to minimize the total loss, the predicted values are assigned to the actual values, one-to-one. To compute these minimum matches, we can use an algorithm called the Hungarian method:
Figure 8. Hungarian loss function
Backbone: extracted features from a convolutional neural network, passed along with the positional encoding
Transformer Encoder: The Transformer is inherently a sequence processing unit, therefore, the incoming tensors are flattened. It transforms the sequence into the same long sequence of features.
Transformer Decoder: A decoder receives Object queries, and has a side input for conditioning information.
Prediction Feed-Forward Network (FFN): The output of this module is fed into a classifier to output the class labels and bounding boxes.
Subscribe to our newsletter and
get the latest practical content.
You can enter your email address and subscribe to our newsletter and get the latest practical content. You can enter your email address and subscribe to our newsletter.