AIEX Deep Learning platform provides you with all the tools necessary for a complete Deep Learning workflow. Everything from data management tools to model traininng and finally deploying the trained models. You can easily transform your visual inspections using the trained models and save on tima and money, increase accuracy and speed.
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
Revolutionary Indsutry Transformation
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
You will be safer at work if you trust intelligent machines!
Since a public, high-quality, and large image dataset of construction vehicles is rare, Arabi et al. from the Department of Civil, Construction, and Environmental Engineering at the Iowa State University, USA, have used a single shot detector MobileNet as an object detection model. After validating the model, further optimization methods such as economic analysis, and field investigation were implemented. The authors suggest a solution to achieve a trade-off between accuracy and deployment costs. The proposed approach by the authors can also be used for several other purposes such as safety monitoring, productivity assessments, and managerial decision-making.
Computer vision in civil engineering
Employing CV in civil engineering is a hot topic nowadays. Crack detection, structural damage detection, transportation network reliability analysis, traffic congestion and incident detection, tunnel-lining defect detection, and pavement crack detection are just some of the possible applications. In this article, we will discuss the use cases and advantages of artificial intelligence (AI) in construction engineering. The following section describes some of the issues faced by the industry and how they can be addressed by AI professionals.
CV in construction engineering
Detecting construction vehicles and workers is necessary to guarantee their safety and maintain security. AI researchers use background subtraction, morphological processing, and neural networks to classify objects. Fuzzy inference and object tracking methods are used to monitor struck-by accidents. However, all mentioned efforts suffer from an inherent lack of generalization. To tackle the issue, the domain-knowledge-based feature selection should be extensively broadened. A deep learning (DL) model can be implemented as an end-to-end alternative solution for automatic feature extraction.
Faster R-CNN models have been broadly used to detect workers without safety helmets and harnesses. Other models such as Inseption V3 and convolutional network-based solutions have been employed to track worker activities. Construction vehicle detection by DL algorithms has also been implemented using transfer learning and R-FCN models. Nonetheless, almost all the mentioned solutions lack real-time on-site operation capability, suffer from low efficiency, and have a high cost of deployment. The only study concerning these issues was done on road damage detection according to the authors’ claim.
The state-of-the-art deep learning approach
The authors propose a novel two-phase approach to solve the discussed obstacles.
Development phase
This phase includes data gathering and preparation, model selection, training, and validation.
Data gathering and preprocessing
Generally, data can be collected in three main ways:
Available large-scale datasets such as ImageNet, the Common Objects in Context (COCO) database, and the Open Image dataset
Web-crawling techniques
Image capturing
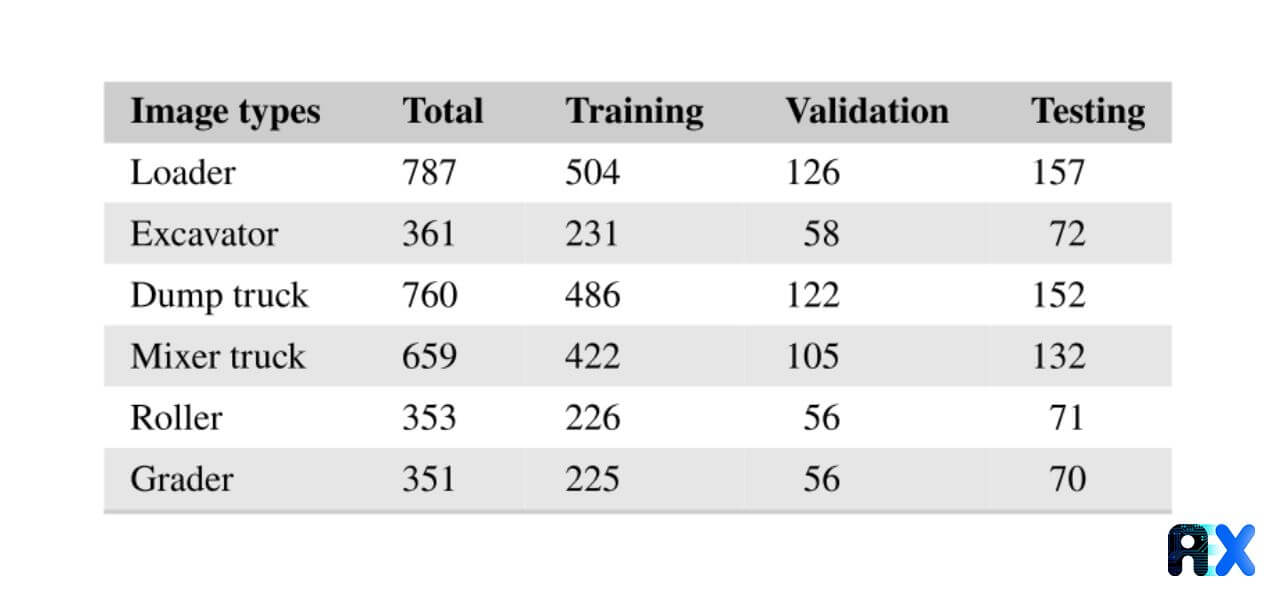
The first two approaches are employed by the authors in this study: They start with the AIM dataset which includes construction vehicle images ( excavators, loaders, rollers, concrete mixer trucks, and dump trucks) originally from the ImageNet dataset and they also crawl the web to extend and enhance the dataset. The additional construction vehicle images are annotated before being split into training (64%), validation (16%), and testing (20%) datasets as presented in Table 1.
Table 1 Dataset details
Some of the challenges in CV-assisted visual inspection include viewpoint variation, scale variation, occlusion, background clutter, and intraclass variation (Figure 1).
Figure 1. Challenges detected by the visual detection of construction equipment: (a) viewpoint variation, (b) scale variation, (c) background clutter, (d) occlusion, and (e) intraclass variation. Source
The proposed detection model
Two general types of object detectors including one-stage and two-stage object detectors have been utilized. Two-stage object detectors exhibit a higher accuracy but use more computational resources, which is not ideal for embedded devices or real-time operations. One-stage detectors, on the other hand, combine these two steps and perform classification and localization using one single network. The authors employ the single shot detector (SSD) and an auxiliary network (i.e., MobileNet) for feature extraction (known as a base network) in this study. The MobileNet can decrease the computation costs by up to eight to nine times.
SSD utilizes the Jaccard overlap (known as IOU) to identify matches. Any proposed box with a Jaccard overlap of 0.5 or greater is recognized as a match. Additionally, an improved version of the cross-entropy classification loss algorithm is applied to improve detector performance. To minimize the loss function and train the network, the Adam optimizer is utilized. And finally, an exponentially decayed learning rate is chosen to train the network.
Training and validation
A high-performance GPU (GeForce GTX 1080Ti) and a 12-Core i7 3.2 GHz Intel CPU were used to train the machine using Tensorflow-GPU 1.12 and CUDA 9. To accelerate and improve the training process and optimize weights, the authors employ a transfer learning method. The training time was about 3 hours.
To evaluate the localization and classification performance of detectors, the PASCAL VOC challenge evaluation metric has been chosen by the authors. By setting different confidence thresholds, authors evaluate precision and recall at different thresholds to determine the overall performance for each category. Average precision (AP) can be calculated by averaging the maximum precision at different recalls. Mean average precision (mAP) is also calculated by averaging APs over all categories. Figure 2 depicts the inference results of the construction vehicle detection model.
Figure 2. Successful vehicle detection with the proposed SSD_MobileNet model. Source
On the other hand, Figure 3 shows false detections including misclassified, merged, missed, and wrong detections. The reason behind the poor performance is the relatively small dataset for training images. By using a training dataset containing various conditions, such as different orientations, scales, locations, and brightness, the detection performance would significantly improve. Finally, the authors complete the deployment phase to optimize the model and deploy it at the real sites.
Figure 3. False detection: (a) misclassified, (b) merged, (c and d) missed, and (e) wrong classification, Source
Deployment phase
In the second phase, model optimization, application-specific hardware selection, and solution evaluation are considered. The paradigm of inference at the edge and the embedded devices is employed. Three distinct embedded devices are used:
NVIDIA Jetson TX2 (NVIDIA Developer) along with TensorRT optimizations (NVIDIA Developer) has been applied as a GPU-accelerated solution for real-time but accurate applications.
Jetson Nano (NVIDIA Developer) with TensorRToptimizations has been utilized as a GPU-accelerated platform for low-demand applications.
Raspberry Pi (R. Pi) 3B+ (Raspberrypi.org) along with Intel Neural Compute Stick (NCS)(Software.intel.com) has been used as an alternative for low-demand applications.
Inference at the edge
Intelligent decision making involves two approaches, namely, cloud-computing-based decision making, and edge-computing-based decision making. Cloud computing consists of computing services such as servers, storage, analytics, databases, etc. delivered over the Internet. Data is collected at the edge of a network (via sensors) before being sent to the cloud for processing and decision-making. This solution suffers from some inherent limitations such as latency and jitter, limited bandwidth, and personal data privacy and security concerns.
The edge-computing paradigm, on the other hand, can gather, store, process, and make a decisionall at the edge of a network. This model also suffers from high deployment and maintenance costs. However, the advantages, such as efficient and fast intelligent decision making, data security, local management, fast recovery from network failure or maintenance, and lower data transfer costs, overcome its limitations.
Details about the three proposed edge computing platforms can be found in the original paper.
Comparing embedded devices
Table 2 summarizes the AP for each category and mAP for the overall performancebefore the model optimization.
Table 2 The AP for each object category and mAP for the overall performance before the model optimization
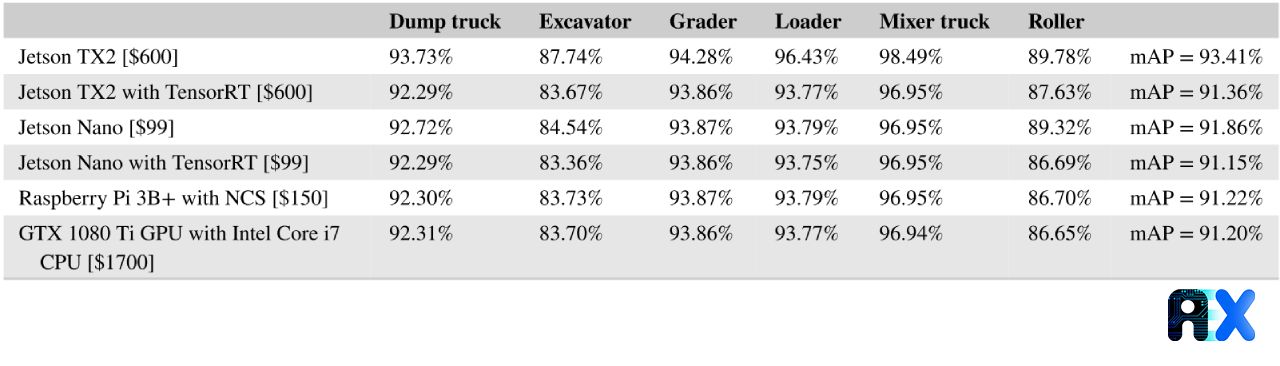
Table 3 presents the AP for each category and mAP for the overall performanceafter the model optimization on embedded systems. The costs associated with each system are also mentioned. Employing TensorRT can significantly enhance the inference speed (from 25 to 47 FPS) at the cost of a slight decrease in the inference accuracy (from 93.41% to 91.36% mAP). This combination is especially ideal for safety and object-tracking applications requiring real-time processing.
Table 3 The AP for each object category and mAP for the overall performance after the model optimization on embedded systems
The Jetson Nano without Tensor RT optimization exhibits the inference speed and accuracy of 13.9 FPS and 91.86% mAP, respectively. Employing Tensor RT optimization increases the inference speed to 22 FPS with an mAP of 91.15%, which is especially beneficial for applications demanding a semi-real-time performance, such as a video-recording trigger in certain situations to improve the management and security of a construction site. According to this paper, the Jetson Nano with TensorRT optimization offers the best cost-performance balance.
Conclusion
The deployment stage is mostly ignored by many deep-learning-based computer vision studies. This paper is the first study regarding construction vehicle detection to address this gap, according to the authors’ claim. In this study, a model is carefully selected by considering the hardware-restricted nature of embedded devices, and an object detection model is trained using an improved SSD_MobileNet.
If you need more information about how AIEX experts can help you, please feel free to contact us.
Subscribe to our newsletter and
get the latest practical content.
You can enter your email address and subscribe to our newsletter and get the latest practical content. You can enter your email address and subscribe to our newsletter.