AIEX Deep Learning platform provides you with all the tools necessary for a complete Deep Learning workflow. Everything from data management tools to model traininng and finally deploying the trained models. You can easily transform your visual inspections using the trained models and save on tima and money, increase accuracy and speed.
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
Revolutionary Indsutry Transformation
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
Trauma Detection on Pelvic Radiographs using Computer Vision Algorithms
Diagnosing proximal femur and pelvis injuries in trauma patients require pelvic radiography images(PXR). PXRs encompass the pelvis and the upper femur area; thus, orthopedic injuries in these regions, including hip fracture, pelvic fracture, hip dislocation, and other associated injuries can be detected in them. Hip fractures are the most frequent fracture type in elderly people; pelvic ring fracture in particular is the most life-threatening fracture and needs special attention. Misdiagnosis or delayed diagnosis, especially in the stressful and chaotic environment of the emergency room (ER) or in local hospitals/rural areas where radiologists may not be available 24/7, leads to unfavorable consequences. Early diagnosis and treatment in the ER may prevent catastrophic outcomes.
Accurately detecting all kinds of pelvic trauma using computer vision (CV) algorithms can prevent misdiagnosis and provide early warning for life-threatening conditions. This state-of-the-art approach has been successfully implemented for several classification projects including diagnosing skin lesions, analyzing retinal images, classifying chest radiography abnormalities, and reading neural images. However, they mostly involve annotating large numbers of medical images, which is often labor-intensive and requires special expertise. Many deep convolutional neural networks (DCNNs) were trained using weak labels (i.e., annotations only indicating the presence/absence of the findings without specifying the exact location) to automatically or semi-automatically diagnose such traumas from medical records at a low cost.
Several studies on fracture detection using weakly supervised learning revealed that the trained models exhibit an accuracy rate comparable to physicians. Convincing physicians to employ such diagnosis algorithms requires a universal AI-based system capable of detecting various pathologies on a single X-ray image. Most works in this field still suffer from a significant performance gap between the model’s prediction and an orthopedic specialist’s or a radiologist’s diagnosis.
Concurrently identifying multiple categories of abnormalities in an image can increase the applicability of trained models in clinical practice. The bottleneck associated with CV models in the medical field is the relatively small number of images and the lack of labeled data. Weakly supervised methods may provide a sufficiently high baseline performance on large but a little noisy data. However, some specific categories of medical images are difficult to be processed.
Chi-Tung Cheng et al. from the department of trauma and emergency surgery at Chang Gung University in Taiwan proposed a universal algorithm called PelviXNet to detect most such trauma-related injuries on PXRs. They incorporated location supervisory signals in the training process using point-based annotation to increase the performance of the model. Thus, an efficient, flexible, and informative labeling method to provide local information was created. PelviXNet can detect all trauma-related radiographic injuries in PXRs, including hip fracture, pelvic area fracture, hip dislocation, periprosthetic fracture, and femoral shaft fracture. The results show that the trained model’s performance in detecting pelvic and hip fractures is comparable to radiologists and orthopedics.
Object detection algorithms are typically fully supervised, given the availability of datasets annotated using bounding boxes (e.g., PASCAL-VOC and MS- COCO). However, defining a bounding box for trauma-related injuries on an image is technically difficult and practically unreliable since it requires extensive clinical experience and is intensive labor to precisely annotate all fracture sites/instances on PXRs. Additionally, some trauma-related findings on PXRs may not have clear boundaries. Hence, a CV algorithm with a cost-effective and flexible annotation scheme is crucial for detecting universal trauma findings on PXRs.
How to Train a Robust Model
Data Sources
A dataset with 5204 PXRs was gathered from the trauma registry of the Chang Gung Memorial Hospital in Taiwan recorded from May 2008 to December 2016 (Figure 1). A total of 3110 images had acute trauma-related radiographic findings, resulting in 4357 annotated points (median 1, range 0–7). The images included 2036 (39.1%) hip fracture images, 919 (17.7%) pelvic area fracture images, 232 (4.5%) images of other abnormalities, and 2094 (40.2%) PXRs without trauma-related radiographic findings. The images were converted to the PNG format for further processing. To identify the trauma-related instances, an image review board consisting of a radiologist, a trauma surgeon, and an orthopedic surgeon with 15, 7, and 3 years of experience, respectively, was employed. The reviewers were asked to annotate the images by marking the center of the trauma-related radiographic findings. The model’s performance is evaluated using an independent clinical scenario test set from the ER registry data recorded from January to December 2017.
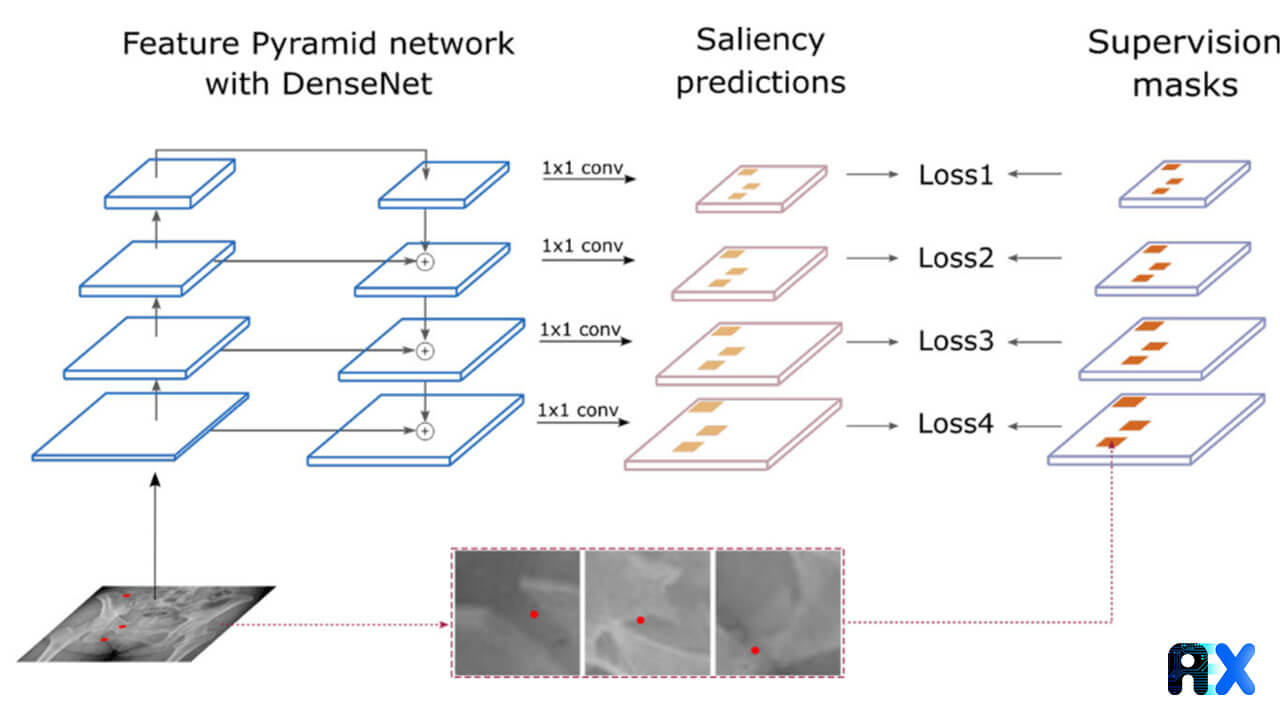
PelviXNet consists of DenseNets, point supervision, and feature pyramid network (FPNs) (Figure 2). The input images are resized to 1024 × 1024 pixels. The output is a 32 × 32 binary classification probability heatmap, revealing the possibility of trauma-related radiographic findings.
Figure 2. The schematic of the bone fracture classification and localization system. Source
A point-based supervision technique extracts the local information during the training process. The training images were inputted into the algorithm several times and the calculated weight inside the network was adjusted. This approach enables the model to universally detect trauma-related radiographic instances. During the inference stage, five models each containing five augmented images were ensembled to generate the final prediction for the image (Figure 3).
Figure 3. The Overview of the ensemble method for inference in testing. Source
Image Pre-processing
The aim of the pre-processing step is to standardize the input size for CNNs and optimize the GPU memory footprint. Image preprocessing was performed using the Python Imaging Library. The following operations were performed for dataset augmentation:
(1) random horizontal and vertical translations with offsets in both directions.
(2) random rescaling
(3) random horizontal flipping
(4) random rotation
(5) brightness and contrast adjustments
Point-based Annotation
Creating bounding box annotations is labor-intensive, and less economically preferable in large-scale medical image datasets. Therefore, the authors used point-based annotations, an efficient and informative labeling method, to easily provide the findings’ localization information. The annotators were asked to place points on visible fracture sites. For complex cases where the fractures could not be clearly defined, the annotators decided to place one or multiple points at their own discretion.
Training the Model
Since radiographic patterns have different scales, DenseNet-169 FPN was used as the backbone feedforward neural network (Figure 2). The FPN outputs multiple levels of feature maps with different spatial resolutions, which can be used to capture objects of different sizes. Object annotations were assigned to different pyramid levels according to their size which is measured using their bounding boxes.
Implementation Details
A single Intel Xeon E5-2650 v4 CPU @ 2.2 GHz, 128 GB RAM, and 4 NVIDIA TITAN V GPUs were used to train the model. The operating system was Ubuntu 18.04 LTS. All codes were written in Python v3.6, and CV models were implemented using PyTorch v1.3. ImageNet was used to pre-train weights for initializing the backbone network, DenseNet-169. The Adam optimizer was used to train the model for 100 epochs with a batch size of 8 and an initial learning rate of 10−5.
Inference with Ensemble Learning
The five best models selected according to their validation area under the receiver operating characteristic curves (AUROCs), could be considered weak learners under the ensemble learning setup. Figure 3 depicts the ensemble learning system at inference time.
Independent Clinical Scenario Test Evaluation
After training the model, the PXR2017 dataset was evaluated using the trained model. The receiver operating characteristic (ROC) and precision-recall (PR) curve were calculated. The sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) were evaluated at the cutoff value.
Comparing results with Physicians’ Performance
50 hip fractures, 50 pelvic area fractures, and 50 normal images were randomly selected from the PXR2017 dataset and included in the PXR150 test set to compare the diagnostic performances of the trained model and the physicians (Figure 4).
Figure 4. The distribution of each data set. Source
Statistical Analysis
All statistical analyses were conducted using R 3.6.3 with “pROC”, “tableone”, “caret”, and “ggplot2” packages. The continuous variables were analyzed with the Kruskal–Wallis rank-sum test, and the categorical variables were compared with the chi-square test and Fisher’s exact test. The AUROC and area under the precision-recall curve (AUPRC) were also calculated. Youden’s J statistic was used to determine the performance of a given cutoff value. The performance of PelviXNet and the physicians with the PXR 150 test set were compared using McNemar’s test.
The Trained Model’s Performance
PelviXNet achieved an overall accuracy of 92.4% in a real-world population dataset. Besides, an independent study comparing PelviXNet with 22 physicians’ diagnoses reported accuracies of 99.5% and 94.5% in hip and pelvic fracture detection tasks, respectively, revealing that PelviXNet outperformed emergency physicians (95.0 and 90.3%) and residents (94.9 and 89.3%) and has comparable performance to that of orthopedic specialists and radiologists (97.4 and 94.0%).
Model’s Performance with Test Set from a Clinical Scenario
Among all cases, 82 (4.3%) were defined as difficult cases, and 9 (0.5%) were considered misdiagnoses. Figure 5 presents PelviXNet’s universal trauma finding detection performance. PelviXNet yields an AUROC of 0.973 and an AUPRC of 0.963 when applied to the clinical population test set of 1888 PXRs. The accuracy, sensitivity, specificity, PPV, and NPV at the cutoff value are 0.924, 0.908, 0.932, 0.867, and 0.954, respectively.
Figure 5. The ROC (a) and PR curve (b) of the universal trauma finding detection using the PelviXNet model. Source
Figure 6 depicts heatmap examples for the visualization of different acute trauma-related findings. Among all 57 false-negative images, hip (5.6%) and pelvic area fractures (15.6%) were the most common findings (Table 1).
Figure 6. Heatmaps overlaid by the algorithm on original images. The red color represents a high probability of acute trauma detection. (a) no fracture, (b) Anterior–posterior compression type pelvic fracture, (c) left femoral non-displaced intertrochanteric fracture, (d) left periprosthetic fracture, (e) right femoral shaft fracture, (f) right hip dislocation, (g) Difficult case of pelvic fracture, (h) Clinically missed pelvic fracture, and (i) Multiple pelvic fractures detected simultaneously by PelviXNet. Source
Table 1 Missed and detected trauma instances.
Comparing results with physicians’ performance.
Physicians mostly performed better in hip fracture detection than in pelvic fracture detection. The PelviXNet’s performance is almost identical to that of radiologists and orthopedic surgeons. Nevertheless, PelviXNet substantially outperformed the ER physicians and residents, especially on the more difficult pelvic fracture detection task. On average, PelviXNet could detect 9%, 5.5%, and 9.7% of pelvic area fractures that were misdiagnosed by ER physicians, consulting physicians, and ER residents, respectively.
Limitations.
PelviXNet’s main limitation is the scarcity of training data. Insufficient training data, such as hip dislocation, will decrease the algorithm’s performance. Another limitation is that the population demography and images collected from them may be biased and might not directly apply to other population distributions. Moreover, in real-world scenarios, physicians make diagnoses based on radiographic findings and other clinical information, such as the patient’s medical history and physical examination results. Future prospective studies are required to validate whether applying PelviXNet as a computer-aided diagnostic system in a clinical environment leads to more precise diagnoses and facilitates trauma patient management.
Conclusions
The proposed model, PelviXNet can successfully identify all kinds of trauma-related abnormalities and localize them correctly with point supervision for the regional information in the image. Computer-aided diagnosis systems can help institutes that lack specialists or can even be used in prehospital settings. Early treatment for hip and pelvic fractures can effectively reduce morbidity and mortality. Some key advantages and limitations of the model are listed below:
PelviXNet can promisingly detect hip fractures.
Missed fractures are mostly intracapsular or complex cases requiring confirmation using advanced imaging modalities.
PelviXNet can detect most pelvic fracture sites, although there are still four unstable pelvic fractures that were missed.
Most of the missed cases were difficult cases.
PelviXNet detected five of the nine misdiagnosed cases.
Adding detailed information to the model may reduce the need for training images and provide better results.
The collaboration between the algorithm and physicians can improve the quality of trauma care.
Dataset Availability
The authors published the test dataset for data validation and academic purposes only.
Code Availability
The code used in this project is also available for academic purposes only and the operation packages can be accessed upon request.
Contact us today to find out how the AIEX platform can be used to train state-of-the-art models for fracture classification or other orthopedic applications.
Subscribe to our newsletter and
get the latest practical content.
You can enter your email address and subscribe to our newsletter and get the latest practical content. You can enter your email address and subscribe to our newsletter.