AIEX Deep Learning platform provides you with all the tools necessary for a complete Deep Learning workflow. Everything from data management tools to model traininng and finally deploying the trained models. You can easily transform your visual inspections using the trained models and save on tima and money, increase accuracy and speed.
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
Revolutionary Indsutry Transformation
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
Logistics monitoring is a piece of cake by computer vision
Many factories worldwide need to deal with complex operations such as shipping, warehousing, courier services, road/rail transportation, air freight, etc as part of their logistics. There are certain downsides if we hire humans for these tasks, such as high costs and inefficiency, poor resources, improper access to vital infrastructures, difficulties in finding skilled workers, and security issues.
There are further bottlenecks in preparing a dataset for logistics. Although plenty of images exist on the web for everyday situations, high-quality logistics images are rare and mostly unrealistic. Moreover, logistics environments almost always include vital information, which can be used by competitors, thus, for economic purposes, they must be secured. Lastly, the privacy of workers must be guaranteed in datasets with real data.
The use of artificial intelligence (AI) including machine learning (ML), deep learning, and computer vision(CV) in complicated tasks such as those in logistics has consistently increased in recent years. Mayershofer et al. from the Technical University of Munich presented a conference paper in the 19th IEEE International Conference on Machine Learning and Applications (ICMLA) to address the above-mentioned issues. They claim to be the first group in the world to release a public dataset specifically for the logistics objects in context (LOCO). It contains pallets, small load carriers, stillages (lattice boxes), forklifts, and pallet trucks in real logistics environments (Figure 1). More importantly, this is the largest dataset in this field with various class imbalances and small-sized objects. The dataset is available on their website.
As state-of-the-art CV approaches, including object classification and detection, or panoptic segmentation, further develop CV is fast becoming a game-changer technology in the automation of complicated processes. The main issue in this regard is the availability of public datasets to be used in ML.
Industry managers, especially in the field of logistics, are not giving enough attention to intelligent machines, mainly because the current datasets generally deal with common scenes and objects, or task-specific use cases such as autonomous driving or remote sensing. However, promoting the capabilities of environmental-perception-enabled machines plays a crucial role in creating an intelligent materials flow.
The overall workflow of logistics object detection
The following steps are implemented by authors to capture images, collect data, train the model, and test it. The data acquisition approach to protect the privacy of workers and the data analysis techniques are also discussed.
How to prepare data
The LOCO dataset contains 39,101 images. First, 5,593 bounding box annotated images were released. Then, they annotated 151,428 images of pallets, small load carriers, stillages, forklifts, and pallet trucks. Authors used a mobile platform in logistics environments to capture real-life images. Images are automatically pre-processed and annotated.
Image recording
Five low-cost, established CV cameras (Microsoft Kinect 2) capture the images to increase the variance in the dataset. To guarantee suitable portability, the cameras are installed on a mobile unit (Figure 2, (a)). The setup provides the facile re-orientation for cameras during the movement of the mobile unit (Figure 2, (b)). To provide a wide view for the camera rig, the cameras are installed both parallel and perpendicular to the movement direction of the mobile unit and at different heights. The mobile unit is further equipped with a mobile power supply (i.e. battery and converter) and two recording computers to store images at a frequency of one Hz in the JPEG format.
Figure 2. Data acquisition with privacy protection. (a) the mobile unit, (b) the camera installation panel, and (c) two-step blurring approach to protect the workers’ privacy. Source
Worker images are also captured during the image acquisition, which violates their privacy. To solve the issue, Mayershofer et al. employed neural networks to automate face recognition and pixelation, before saving images on the hard drive (Figure 2, (c)). This step is doubled checked by a manual annotation step to avoid any possible false positives.
Image pre-processing
In this step, 64,993 color images are pre-processed and annotated. The image pre-processing procedure includes three steps:
Step 1: Eliminating blurred images Images might be extensively blurred, unrecognizable, and un-annotatable due to the motion of the camera rig. To measure blurriness, a variance of the Laplacian algorithm has been implemented. Finally, 17,109 images were eliminated at this stage.
Step 2: Eliminating similar images To get a high information entropy for each image, simplify the annotation effort, and ensure dataset balance, similar images should be removed. Images are sorted based on timestamp, and the structural similarity between two consecutive images is evaluated. In sum, 8,783 images were removed at this stage.
Step 3: Random sampling In the last step, 15% of the remaining images were randomly chosen for annotation to maximize the information entropy while minimizing the annotation effort.
Image annotation
The COCO-Annotator algorithm was employed for image annotation using bounding boxes. The authors developed the annotator in the form of a dedicated bounding box tool, new hotkeys, and additional automation to promote a more ergonomic, efficient, and smooth labeling procedure. In the last step, they employed a blurring algorithm to automatically blur faces not detected by the neural network. The annotators were trained using images before performing their tasks. Consequently, the annotated images were used to validate the model. Figure 3 depicts LOCO sample images after annotating.
The Darknet and Detectron2 frameworks are employed by authors to train YOLOv4-608, YOLOv4-tiny, and Faster R-CNN (R50-FPN-3x). Meanwhile, they took advantage of pre-trained weights available in each model zoo and fine-tuned them on the LOCO dataset with standard training settings provided by each framework.
Model validation
Unlike common datasets, the authors do not randomly split data. Instead, they use subsets for splitting data into training and evaluating datasets since each subset contains images of one particular logistics item. Five subsets are defined, in which three subsets are assigned to the training dataset and the other two are utilized for model validation purposes. To evaluate the model, the mean average precision (mAP) was calculated as the key performance indicator.
Evaluation of the model performance for the LOCO dataset
The authors provide an in-depth analysis of LOCO, compare it to other datasets (i.e. OpenImages and MS COCO) and claim that their model contains more annotations per image with noticeably smaller annotations compared to others.
Statistics evaluation
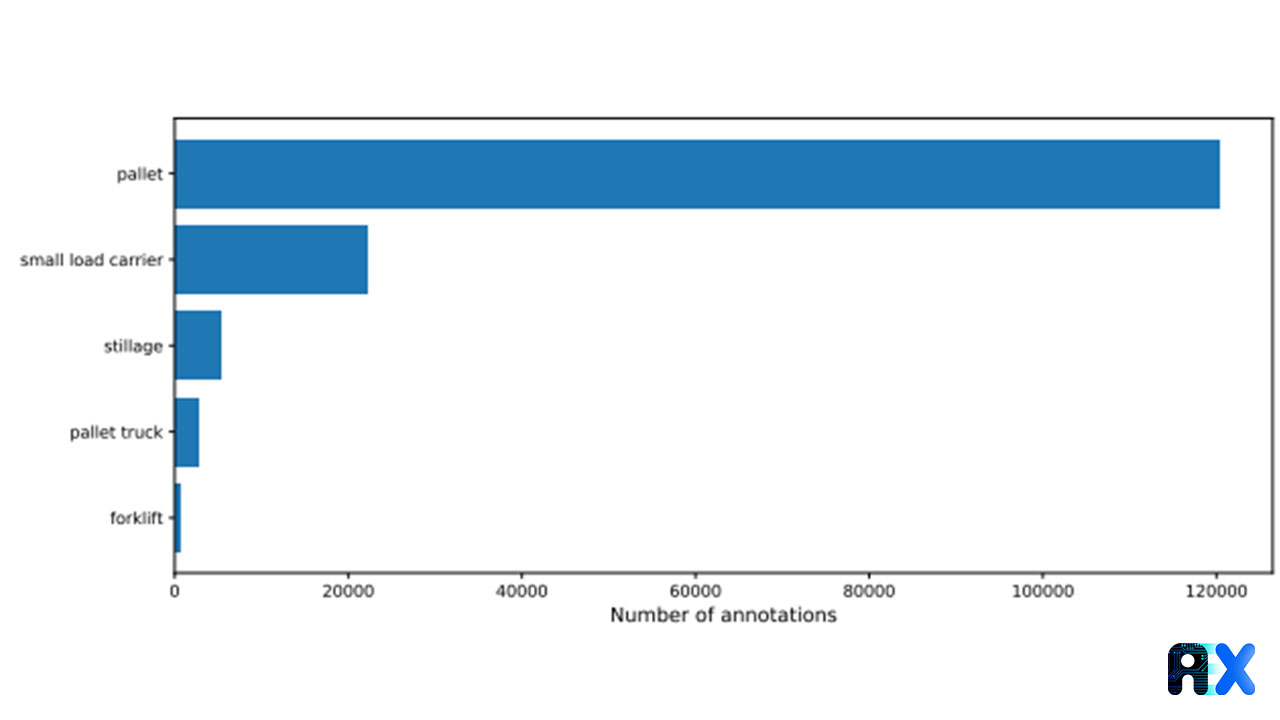
The LOCO dataset was analyzed with respect to object class distribution, number of annotations per image, and object size distribution. Then, results were compared to COCO and OpenImages datasets. The object class distribution is unbalanced with respect to the annotated items (Figure 4).
Figure 4. Annotation number per class in the LOCO dataset. Source
Only half of the images in common datasets are annotated with fewer than five annotations per image whilst the LOCO dataset exhibits on average 31.1 annotations per image. In Addition, 90% of LOCOs’ annotations demonstrate a relative bounding box size of less than 2% whereas less than 25% of OpenImages’ annotations and approximately 70% of COCOs’ annotations show the same relative size. These results prove that there are significantly smaller annotations in the LOCO dataset.
Performance evaluation
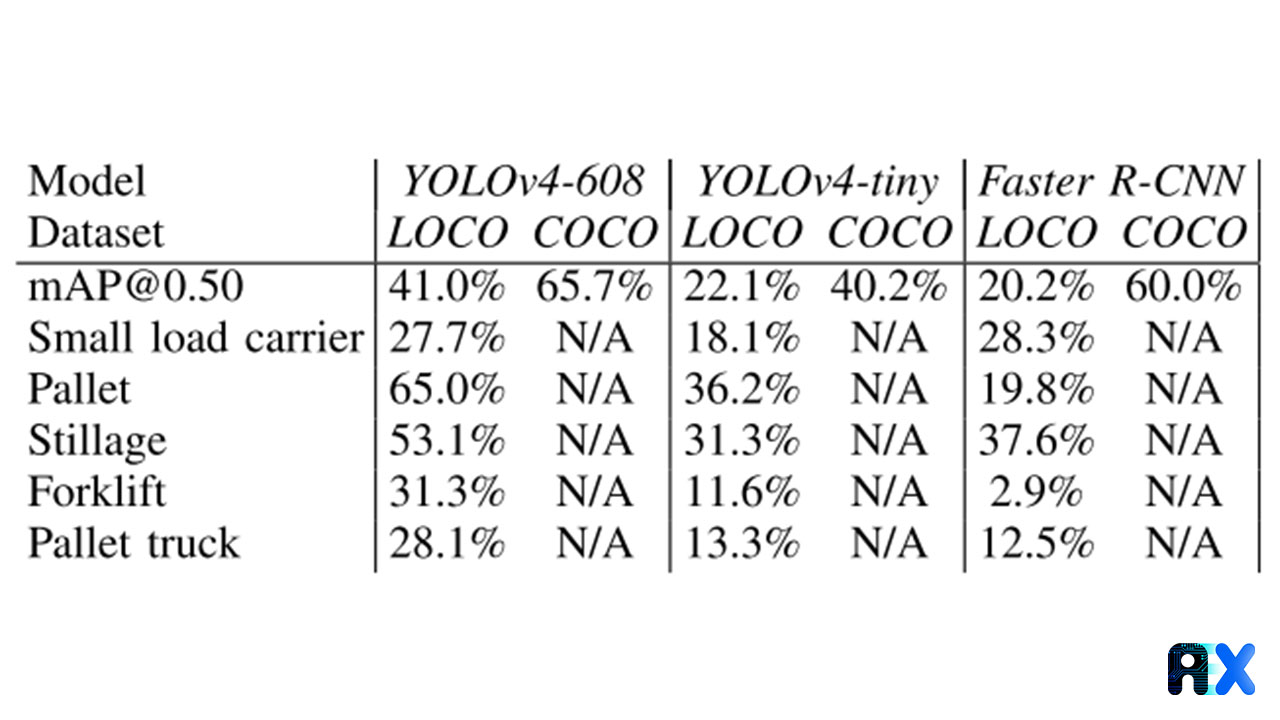
An intersection over union (IoU) of 0.50 was selected. Table 1 presents and compares mAP in different subsets. An mAP of 41.0%, 22.1% and 20.2% is achieved for YOLOv4-608, YOLOv4-tiny, and Faster R-CNN, respectively. Considering mAP@0.50 alone, all models exhibit worse on the LOCO dataset compared to the COCO dataset. On average, the fine-tuned models on the LOCO dataset show 27.5% (mAP@0.50) less than the COCO baseline.
Table 1. Model evaluation for YOLOv4-608, YOLOv4-Tiny, and Faster R-CNN Trained on LOCO
Conclusion and future perspective
The first dataset focusing on scene understanding in logistics environments (LOCO) is introduced and discussed. Currently, LOCO consists of 39,101 images of which 5,593 were annotated and 151,428 images of pallets, small load carriers, stillages, forklifts, and pallet trucks were labeled. The dataset and the approach employed by the authors are suitable for autonomous mobile robots and the use of CV in industrial applications.
Subscribe to our newsletter and
get the latest practical content.
You can enter your email address and subscribe to our newsletter and get the latest practical content. You can enter your email address and subscribe to our newsletter.