AIEX Deep Learning platform provides you with all the tools necessary for a complete Deep Learning workflow. Everything from data management tools to model traininng and finally deploying the trained models. You can easily transform your visual inspections using the trained models and save on tima and money, increase accuracy and speed.
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
Revolutionary Indsutry Transformation
So far we had 3 industrial revolutions, each reducing reliance on human labor and utilizing unmanned systems more than before, we believe the last major uncharted teritory in unmanned systems is the intelligence sub-systems and that’s the defining point of 4th industrial revolution.
Computer vision can help us with agriculture: A case study of defects in fruits
Computer vision (CV) can address some of the needs of the agriculture industry. The ever-growing world population creates more and more demands for agricultural products. This creates a need to monitor the quality of such products, with more efficient and effective methods in order to recognize and classify them by quality in bulk processing. Artificial intelligence (AI), especially CV, plays a critical role in replacing skilled staff with machines for quality inspection and classification. However, quality control (QC) of agricultural products using CV is not a simple task since the intensity, shape and size, contour, and texture features extracted from fruits are quite varied.
Nutrient deficiency causes deformation in fruits or grains. Potassium, nitrogen, and phosphorus deficiencies can be detected by the color of the leaves. Nitrogen deficiency limits growth and is responsible for fast wilt rates. To prevent these deficiencies and other conditions, trees and their fruits can be constantly monitored using image processing and applying k-means clustering. Moreover, color images can be analyzed through the convolutional neural network models (CNN) with a high classification accuracy of 86.2% which enables AI-powered machines to also predict the ripeness of the fruits.
Additionally, defective fruits may damage the economy and the ecology of a country. By employing CV in the agriculture industry, not only the quality and productivity of agricultural products can be improved, but the country’s economy can also be protected and even further developed.
Recently, Dr. Yogesh et al. from the Amity University Uttar Pradesh in India investigated the detection of defective parts of fruits using CV. They used a support vector machine (SVM) classifier to categorize fruits into two groups, including perfect and defective, and clarify the causes along with the degree of defectiveness(from 3 levels). According to the paper published by authors in the journal of cluster computing (2020), the major obstacle in the automatic identification of disease is the lack of an appropriate image dataset. To address this issue, data augmentation methods have been employed by several researchers.
Workflow
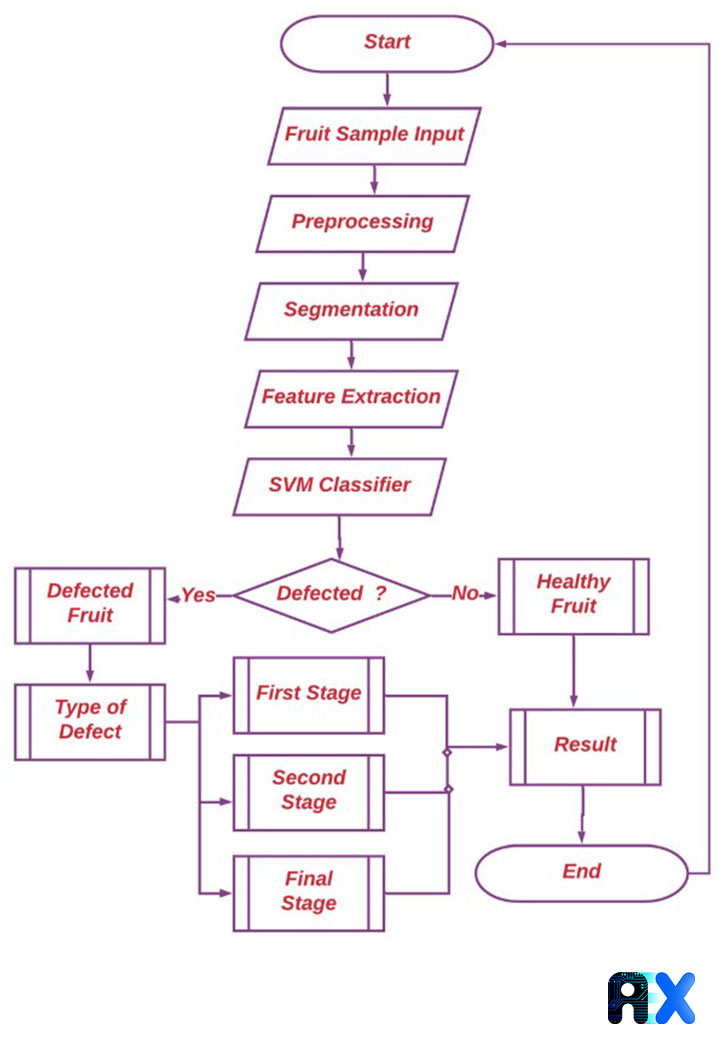
They start with images of some fruits such as apples, lychee, pear, mosambi, and pomegranate. The brightness and contrast of images are adjusted before noise is eliminated (image pre-processing). Next, images are segmented into multiple parts with similar attributes. By performing this process, the image background is removed, and defective regions are segmented. Afterward, geometric shape, texture and statistical characteristics of the defective regions are extracted. Finally, their features are determined by the SVM classifier and the model accuracy is calculated. The flowchart of the entire procedure is illustrated in Figure 1, which explains more details about each step:
Figure 1. Flowchart of the overall workflow to identify defective fruits and the defect area, Source.
Image acquisition
About 2000 fruit images are captured in standard conditions using a 13 MP CMOS camera with a resolution of 1920 * 1080 pixels at a distance of 60 cm. The image is then resized to 120 * 120 pixels in JPEG format
Image pre-processing
To eliminate noise, image features are exaggerated before the image processing step. In this step, the distorted pixels are reconstructed by averaging the values of adjacent pixels. In fact, through this process, the brightness and contrast of images are enhanced. In addition, the geometric transform excludes any distortion coming from a different position.
Image segmentation
Image segmentation takes images as input and outputs features extracted from the images. Pixels with similar attributes are clustered in a category. This step is one of the most critical steps, determining the success or failure of a CV model, and includes predefined tasks such as thresholding, region split and merge, and region-growing.
In thresholding, the foreground and background are detached according to the mean value of pixels. Through this step, data complexity is minimized, leading to easier image recognition and classification.
In clustering, the objects with similar attributes are split before remerging. By using an edge detection method, the image can be smoothed since the image brightness is intensively changed at the edges.
In Region-growing, adjacent pixels with a similar brightness in a similar region are classified. This step is generally performed by a statistical test determining which pixels should be added to a region.
Feature extraction
Image features are extracted from an image, to provide more comprehensive information about the image. Statistical tests in certain regions and backgrounds are performed for feature detection. This step helps machines learn quicker and easier; it is also another critical step in image processing by a CV model as it converts visual data to non-visual data.
Feature matching
During the Feature matching step the model uses a distance search to find related image features in two similar datasets called the source and the target. In this step, attributes are transmitted from source to target data via a defined distance function matching two descriptors. The distance ratio determines the difference between the two features. When the ratio is close to one, the feature matching is poor.
Defect classification
Classifiers like decision tree, artificial neural network (ANN), SVM, Bayesian, etc. are learning algorithms that calculate a hyperplane splitting the inconsistently classified data.
Defect recognition
Like object detection in CV, there are two methods for defect recognition using deep learning algorithms. First, is training a model from scratch, including a massive training dataset and a CNN-based layers generation. The Second option is transfer learning, including fine-tuning a pre-trained model using a platform such as AlexNet or GoogleNet and inserting a new dataset of unknown classes. The latter method works much faster than the first one since the model has previously been trained on thousands of images.
Performance evaluation
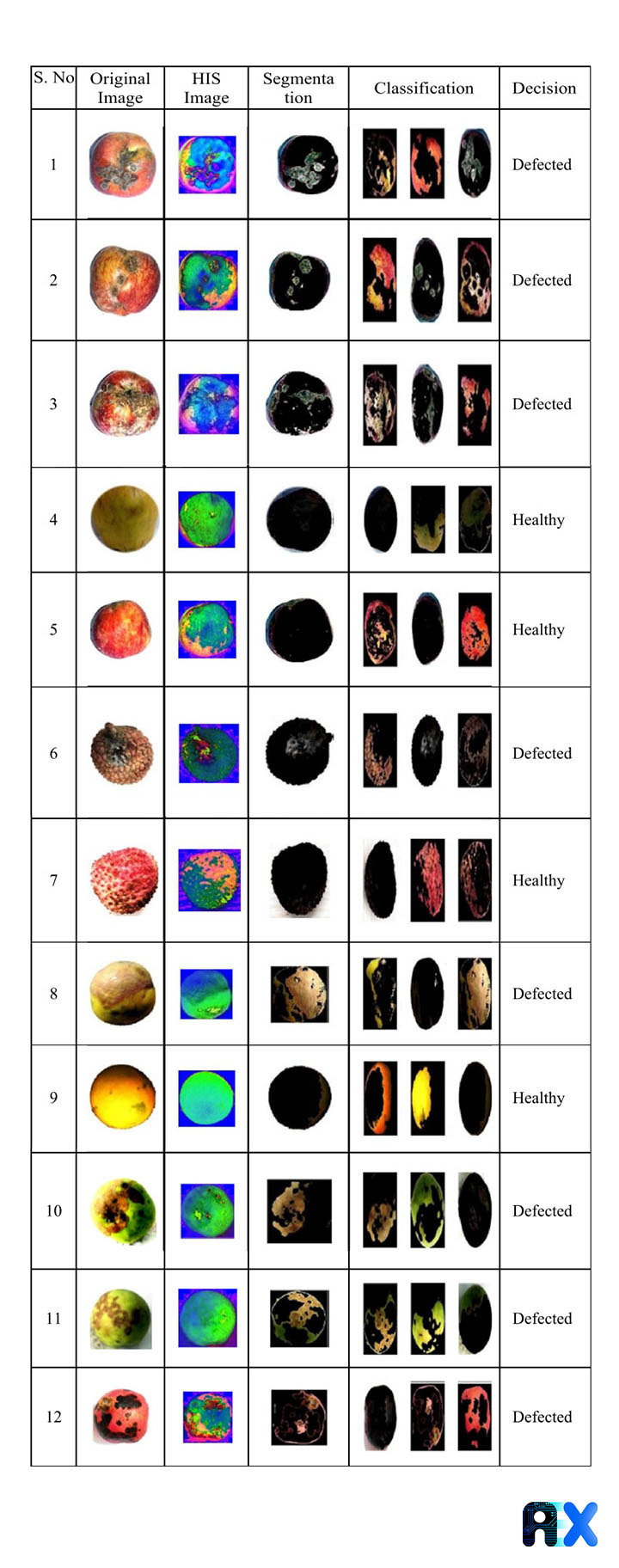
The highest average defect detection accuracy of 98.5% has been achieved in classifying apples. The results for some samples are shown in Table 1.
Table 1. The results of step-by-step procedures and the final decision of the proposed SVM model for the defect detection of fruits
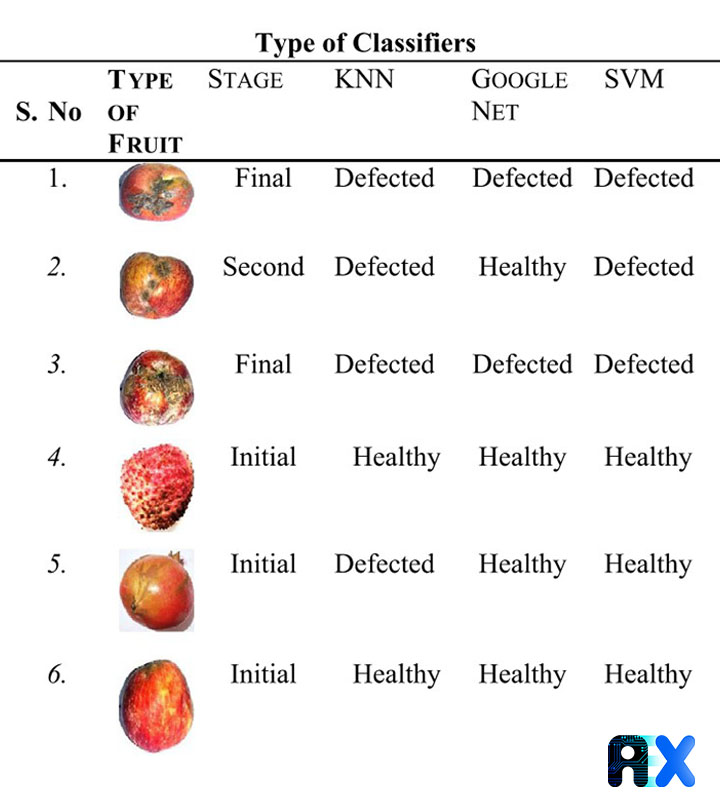
Compared to other methods such as KNN and Google Net with classification accuracies of 89.4 and 79.4%, respectively, the proposed model exhibits a better performance (Table 2).
Table 2. The comparison of the proposed model (SVM) with other image classifiers
Conclusion
Dr. Yogesh et al. proposed a CV-based method for defect detection caused by nutrient deficiency in fruits. Fruits are categorized into two groups of healthy and defective. The defective class is further sub-classed into the first, second, and final stages. The classification accuracy of the suggested SVM classifier is higher than that of KNN and GoogleNet in terms of detecting defective products and their degree of defectiveness. The findings pave the way for the automatic defect detection of fruits in real-time.
Subscribe to our newsletter and
get the latest practical content.
You can enter your email address and subscribe to our newsletter and get the latest practical content. You can enter your email address and subscribe to our newsletter.