Tag: ai
-

Applications of Computer Vision in waste management
This article discusses the integration of artificial intelligence in the field of recycling. We will also train a model on the AIEX platform that can effectively sort waste materials using computer vision technology.
-
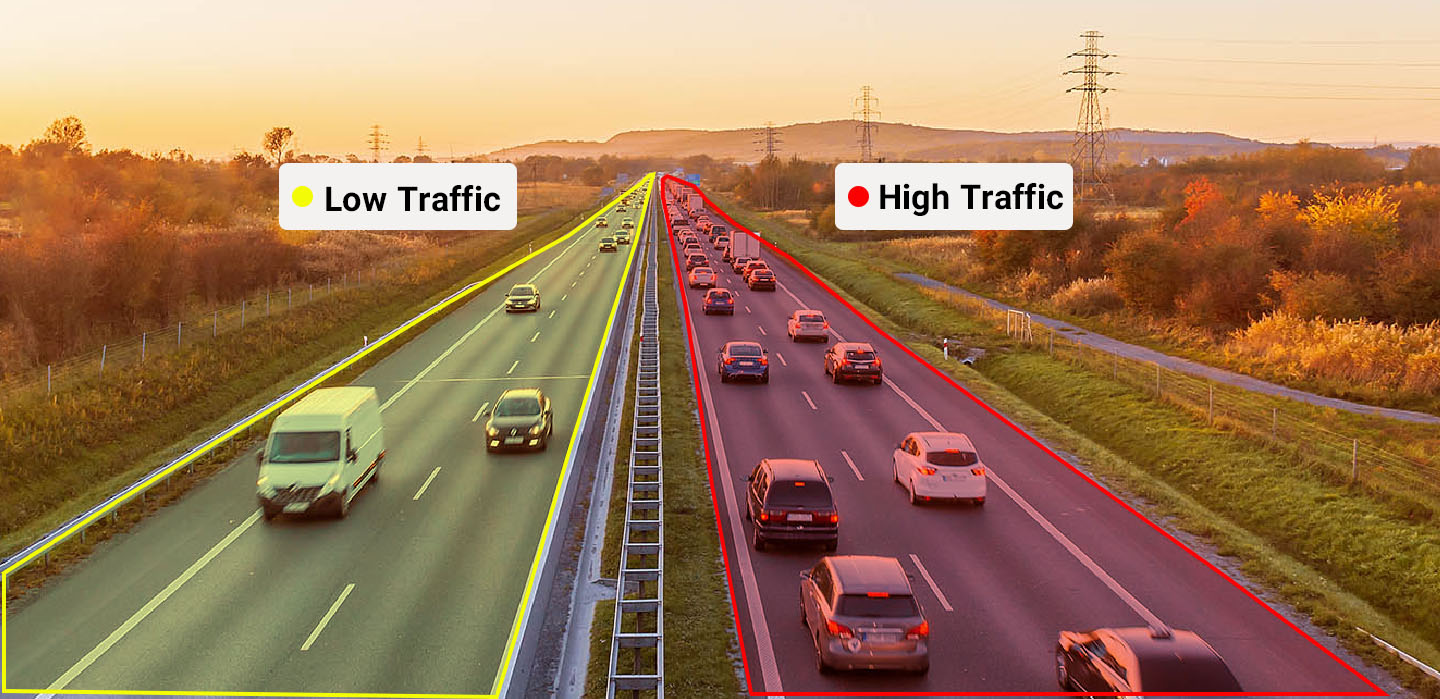
Intelligent traffic management systems
As urban areas continue to grow, the number of vehicles on the road is increasing, which leads to congested traffic and increased travel times. In this article, we will explore the use of Artificial Intelligence in Intelligent Traffic Management Systems, to address these issues and improve the flow of traffic.
-

Ensemble Machine Learning
Ensemble machine learning is a powerful technique that leverages the strengths of multiple weak learning models, also known as base models, to improve the accuracy and stability of predictions. Ensemble methods can produce more robust and reliable predictions than any single model alone. This approach is particularly useful in complex problems where a single model…
-
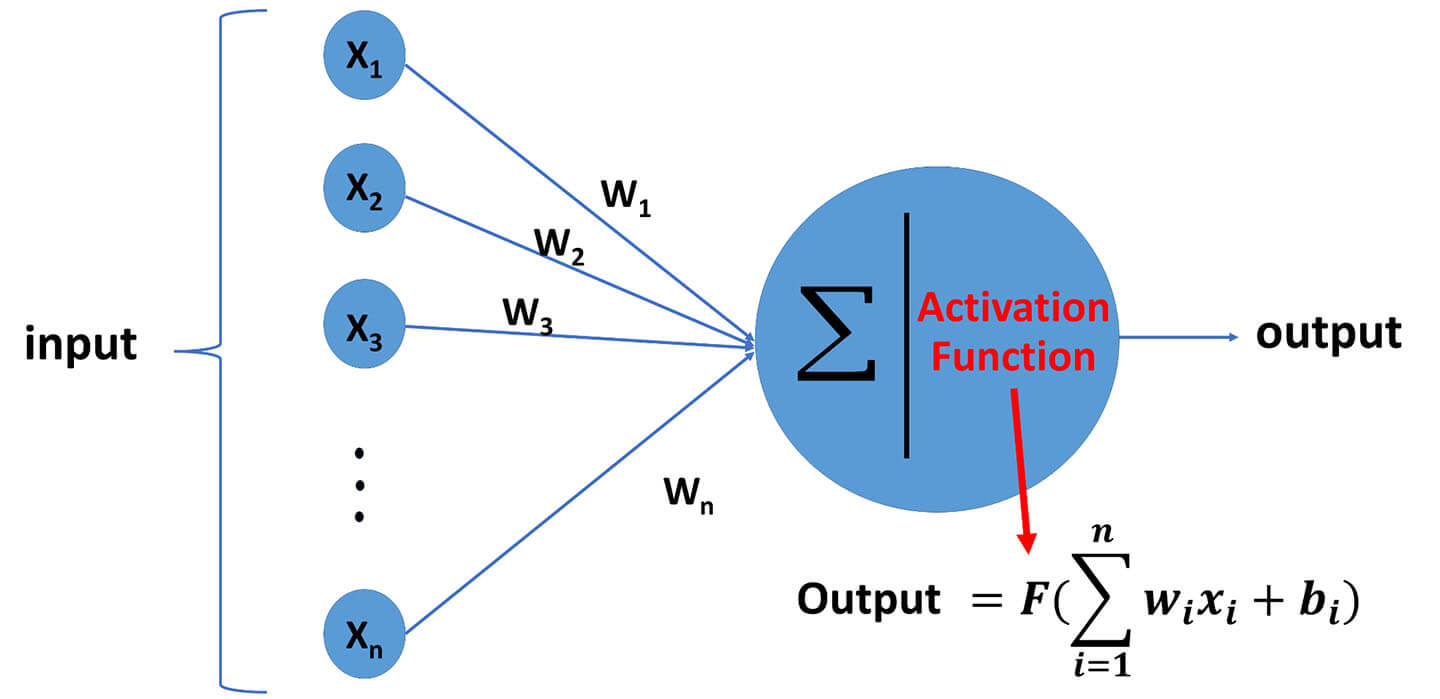
Activation Functions in Neural Network
Activation functions are the main components of neural network nodes. This article examines the various types of activation functions and their importance.
-
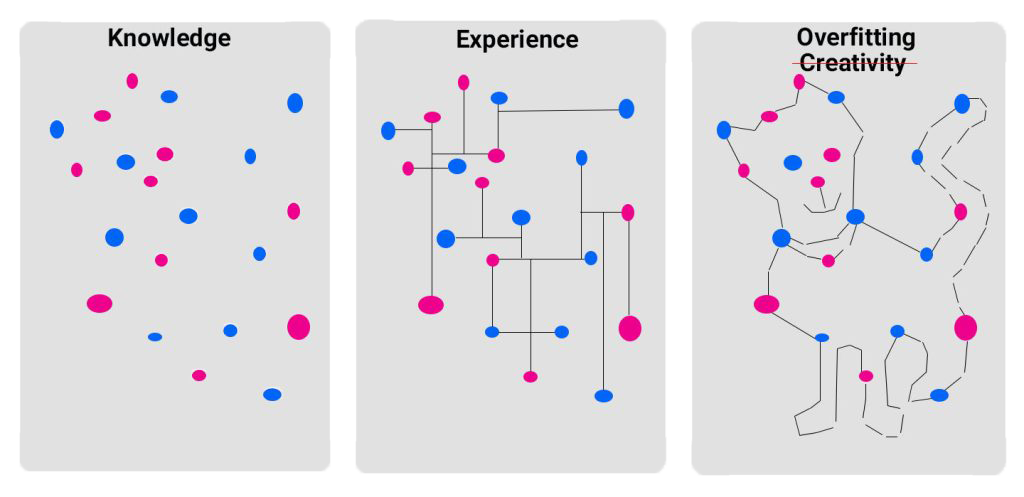
Various Types of Regularization
Regularization is a technique used in Machine Learning and Deep Learning models to prevent overfitting. This paper introduces L1, L2, and dropout regularization methods.
-

Machine Learning Engineers Should Use Docker
Docker is a platform that enables developers to easily create, deploy, and run applications in containers, and has gained immense popularity since its public release in 2013. In this article, we will provide a brief introduction to Docker, and explore its application in the field of machine learning, where it can be used to create…
-

TPU, GPU, CPU: Which Is Better for Deep Learning?
In this paper, we compare the performance of CPU, GPU, and TPU processors to see which one is better suited to deep learning.
-

The History of AI (part 2)
In the second part of a series of articles about the history of artificial intelligence, we look at important published papers in the history of AI and the concept introduced in them.
-

Projects Basics in AIEX Platform
In this paper, we cover the basics of projects. We describe the different types of projects, how to create new projects from existing ones, how to import and export projects, how to use tags and descriptions, and provide some best practices.
-

Organizations, Members & Access Level Management on the AIEX Platform
Training a highly accurate computer vision model requires many carefully annotated images. Data gathering and annotation take time and might often prove to be hard. As the saying goes, nothing is particularly hard if you divide it into small jobs (and assign it to a team of people). This chapter details the teamwork tools implemented…